Parallelization
What you'll learn
- How Cypress balances spec files across multiple machines
- How to run tests in parallel across multiple machines
- How to group test runs and why you might want to
- How to visualize parallelization and groups in Cypress Cloud
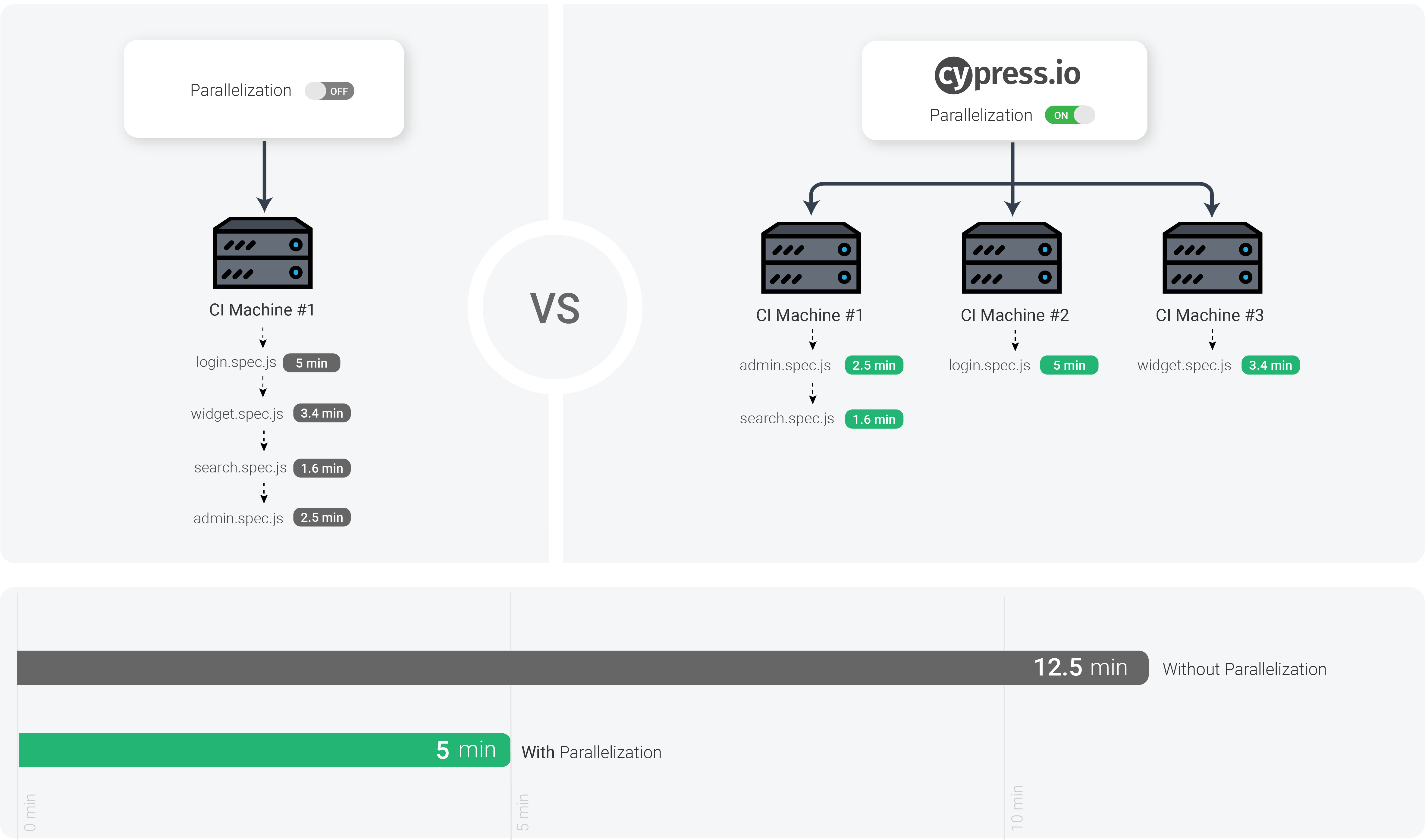
If your project has a large number of tests, it can take a long time for tests to complete running serially on one machine. Running tests in parallel across many virtual machines can save your team time and money when running tests in Continuous Integration (CI).
Cypress can run recorded tests in parallel across multiple machines. While parallel tests can also technically run on a single machine, we do not recommend it since this machine would require significant resources to run your tests efficiently.
This guide assumes you already have your project running and recording within Continuous Integration. If you have not set up your project yet, check out our Continuous Integration guide. If you are running or planning to run tests across multiple browsers (Firefox, Chrome, or Edge), we also recommend checking out our Cross Browser Testing guide for helpful CI strategies when using parallelization.
Splitting up your test suite
Cypress' parallelization strategy is file-based, so in order to utilize parallelization, your tests will need to be split across separate files.
Cypress will assign each spec file to an available machine based on our balance strategy. Due to this balance strategy, the run order of the spec files is not guaranteed when parallelized.
Turning on parallelization
-
Refer to your CI provider's documentation on how to set up multiple machines to run in your CI environment.
-
Once multiple machines are available within your CI environment, you can pass the --parallel key to cypress run to have your recorded tests parallelized.
cypress run --record --key=abc123 --parallel
Running tests in parallel requires the
--record flag be passed. This
ensures Cypress can properly collect the data needed to parallelize future runs.
This also gives you the full benefit of seeing the results of your parallelized
tests in Cypress Cloud. If you have not set up
your project to record, check out our
setup guide.
CI parallelization interactions
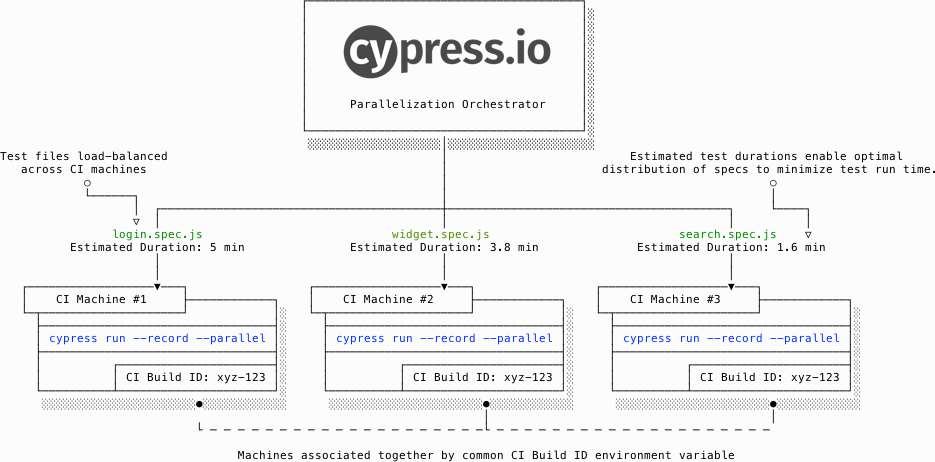
During parallelization mode, Cypress Cloud interacts with your CI machines to orchestrate the parallelization of a test run via load-balancing of specs across available CI machines by the following process:
- CI machines contact Cypress Cloud to indicate which spec files to run in the project.
- A machine opts in to receiving a spec file to run by contacting Cypress.
- Upon receiving requests from a CI machine, Cypress calculates the estimated duration to test each spec file.
- Based on these estimations, Cypress distributes (load-balances) spec files one-by-one to each available machine in a way that minimizes overall test run time.
- As each CI machine finishes running its assigned spec file, more spec files are distributed to it. This process repeats until all spec files are complete.
- Upon completion of all spec files, Cypress waits for a configurable amount of time before considering the test run as fully complete. This is done to better support grouping of runs.
In short: each Cypress instance sends a list of the spec files to Cypress Cloud, which sends back one spec at a time to each application to run.
Parallelization process
Example
The examples below are from a run of our Kitchen Sink Example project. You can see the results of this run on Cypress Cloud.
Without parallelization
In this example, a single machine runs all spec files serially. Below is an
example .circleci/config.yml using the
Cypress CircleCI Orb:
version: 2.1
orbs:
cypress: cypress-io/cypress@6
workflows:
build:
jobs:
- cypress/run:
start-command: 'npm run start'
cypress-command: 'npx cypress run --record'
Cypress runs all 19 spec files one by one alphabetically. It takes 1:51 to complete all of the tests.
1x-electron, Machine #1
--------------------------
-- actions.cy.js (14s)
-- aliasing.cy.js (1s)
-- assertions.cy.js (1s)
-- connectors.cy.js (2s)
-- cookies.cy.js (2s)
-- cypress_api.cy.js (3s)
-- files.cy.js (2s)
-- local_storage.cy.js (1s)
-- location.cy.js (1s)
-- misc.cy.js (4s)
-- navigation.cy.js (3s)
-- network_requests.cy.js (3s)
-- querying.cy.js (1s)
-- spies_stubs_clocks.cy.js (1s)
-- traversal.cy.js (4s)
-- utilities.cy.js (3s)
-- viewport.cy.js (3s)
-- waiting.cy.js (5s)
-- window.cy.js (1s)
Notice that when adding up the spec's run times (0:55), they add up to less than the total time for the run to complete (1:51) . There is extra time in the run for each spec: starting the browser, encoding and uploading the video to the dashboard, requesting the next spec to run.
With parallelization
When we run the same tests with parallelization, Cypress uses its
load balance strategy
to order to specs to run based on the spec's previous run history. During the
same CI run as above, we ran all tests again, but this time with
parallelization across 2 machines. By adding parallelism: 2 and the
--parallel flag to the .circleci/config.yml:
version: 2.1
orbs:
cypress: cypress-io/cypress@6
workflows:
build:
jobs:
- cypress/run:
parallelism: 2
start-command: 'npm run start'
cypress-command: 'npx cypress run --record --parallel'
It finished in 59 seconds.
2x-electron, Machine #1, 9 specs 2x-electron, Machine #2, 10 specs
-------------------------------- -----------------------------------
-- actions.cy.js (14s) -- waiting.cy.js (6s)
-- traversal.cy.js (4s) -- navigation.cy.js (3s)
-- misc.cy.js (4s) -- utilities.cy.js (3s)
-- cypress_api.cy.js (4s) -- viewport.cy.js (4s)
-- cookies.cy.js (3s) -- network_requests.cy.js (3s)
-- files.cy.js (3s) -- connectors.cy.js (2s)
-- location.cy.js (2s) -- assertions.cy.js (1s)
-- querying.cy.js (2s) -- aliasing.cy.js (1s)
-- location.cy.js (1s) -- spies_stubs_clocks.cy.js (1s)
-- window.cy.js (1s)
The difference in running times and machines used is very clear when looking at the Machines View on Cypress Cloud. Notice how the run parallelized across 2 machines automatically ran all specs based on their duration, while the run without parallelization did not.
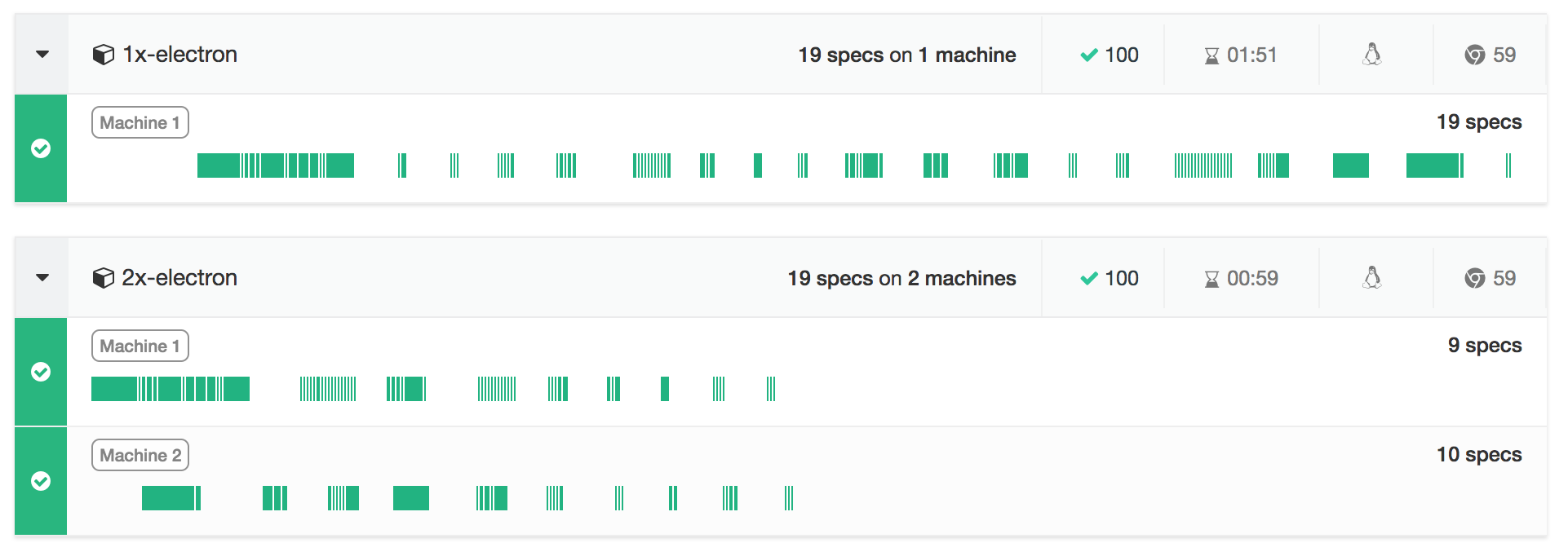
Parallelizing our tests across 2 machines saved us almost 50% of the total run time, and we can further decrease the build time by adding more machines.
Grouping test runs
Multiple cypress run calls can be
labeled and associated to a single run by passing in the
--group <name> flag,
where name is an arbitrary reference label. The group name must be unique
within the associated test run.
For multiple runs to be grouped into a single run, it is required for CI machines to share a common CI build ID environment variable. Typically these CI machines will run in parallel or within the same build workflow or pipeline, but it is not required to use Cypress parallelization to group runs. Grouping of runs can be utilized independently of Cypress parallelization.
Grouping test runs with or without parallelization is a useful mechanism when implementing a CI strategy for cross browser testing. Check out the Cross Browser Testing guide to learn more.
Grouping by browser
You can test your application against different browsers and view the results under a single run within Cypress Cloud. Below, we name our groups the same name as the browser being tested:
The first group can be called Windows/Chrome 69.
cypress run --record --group Windows/Chrome-69 --browser chrome
The second group can be called Mac/Chrome 70.
cypress run --record --group Mac/Chrome-70 --browser chrome
The third group can be called Linux/Electron. Electron is the default
browser used in Cypress runs.
cypress run --record --group Linux/Electron
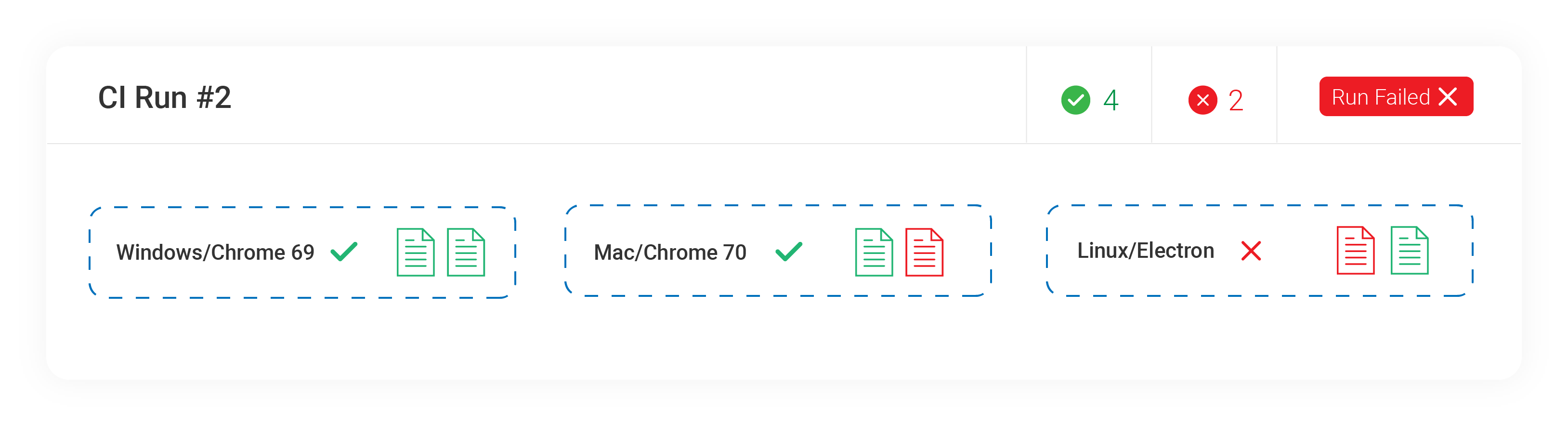
Grouping to label parallelization
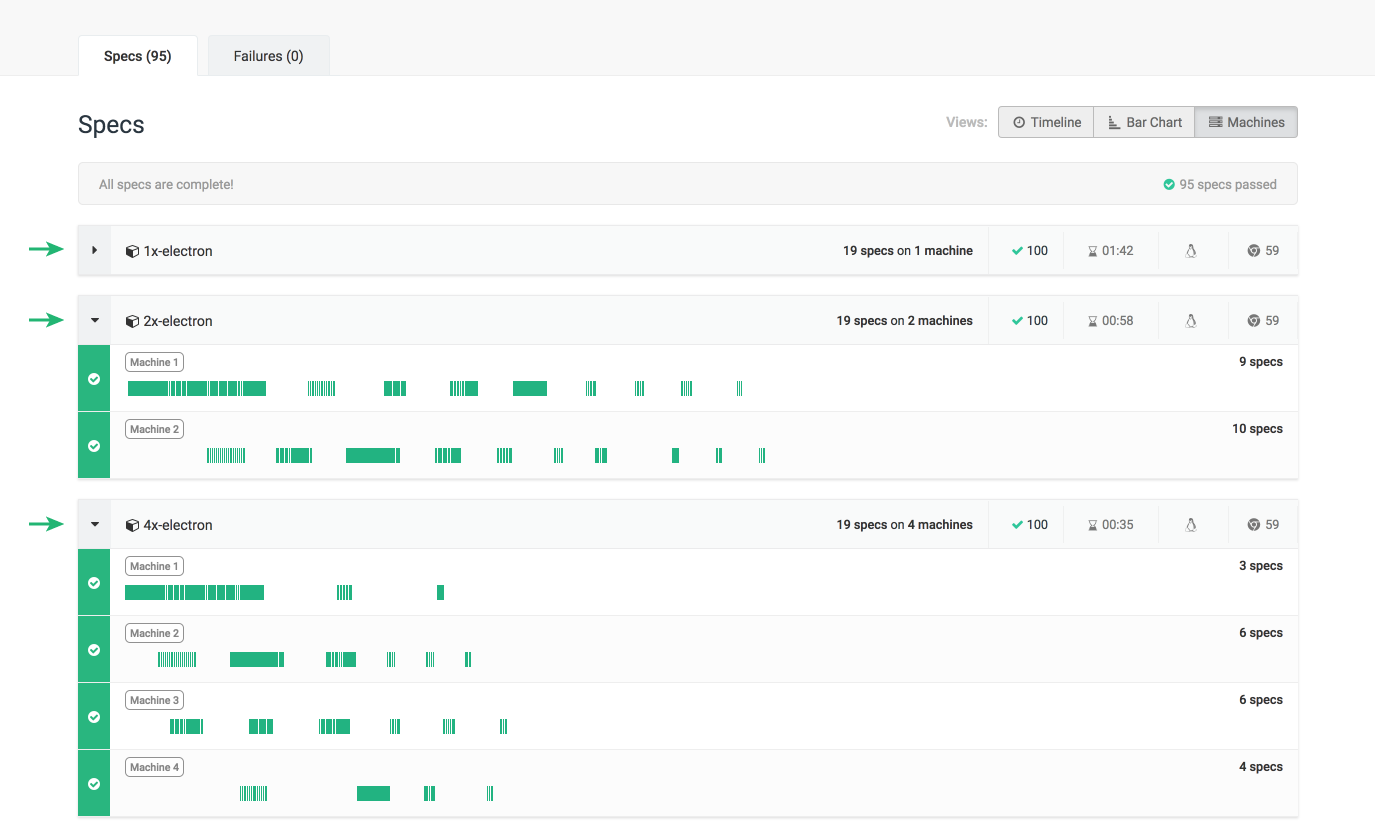
We also have the power of Cypress parallelization with our groups. For the sake of demonstration, let's run a group to test against Chrome with 2 machines, a group to test against Electron with 4 machines, and another group to test against Electron again, but only with one machine:
cypress run --record --group 1x-electron
cypress run --record --group 2x-chrome --browser chrome --parallel
cypress run --record --group 4x-electron --parallel
The 1x, 2x, 4x group prefix used here is an adopted convention to indicate
the level of parallelism for each run, and is not required or essential.
The number of machines dedicated for each cypress run call is based on your CI
configuration for the project.
Labeling these groups in this manner helps up later when we review our test runs in Cypress Cloud, as shown below:
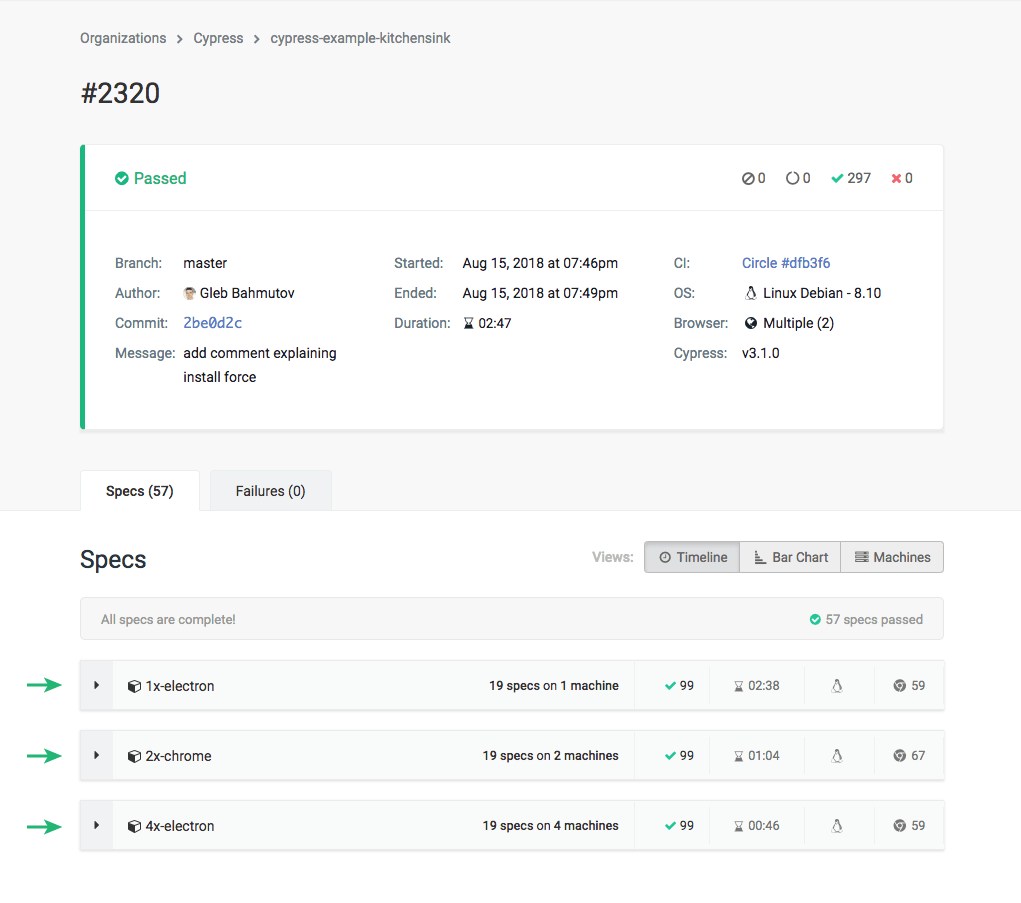
Grouping by spec context
Let's say you have an application that has a customer facing portal, guest facing portal and an administration facing portal. You could organize and test these three parts of your application within the same run:
One group can be called package/admin:
cypress run --record --group package/admin --spec 'cypress/e2e/packages/admin/**/*'
Another can be called package/customer:
cypress run --record --group package/customer --spec 'cypress/e2e/packages/customer/**/*'
The last group can be called package/guest:
cypress run --record --group package/guest --spec 'cypress/e2e/packages/guest/**/*'
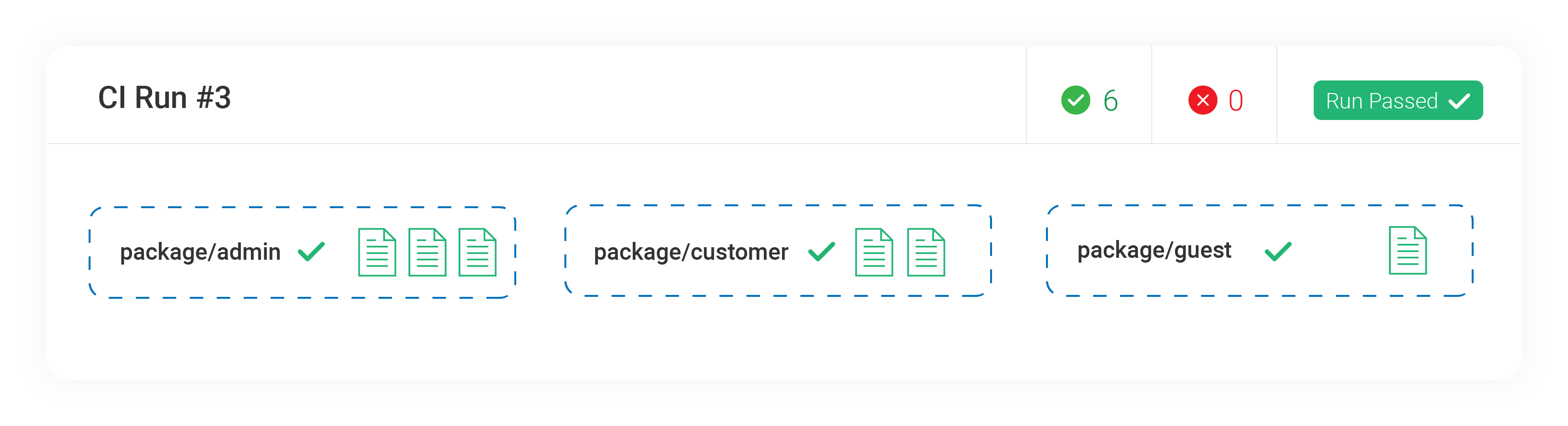
This pattern is especially useful for projects in a monorepo. Each segment of the monorepo can be assigned its own group, and larger segments can be parallelized to speed up their testing.
Linking CI machines for parallelization or grouping
A CI build ID is used to associate multiple CI machines to one test run. This
identifier is based on environment variables that are unique to each CI build,
and vary based on CI provider. Cypress has out-of-the-box support for most of
the commonly-used CI providers, so you would typically not need to directly set
the CI build ID via the
--ci-build-id flag.

CI Build ID environment variables by provider
Cypress currently uses the following CI environment variables to determine a CI build ID for a test run:
| Provider | Environment Variable |
|---|---|
| AppVeyor | APPVEYOR_BUILD_NUMBER |
| AWS CodeBuild | CODEBUILD_INITIATOR |
| Azure Pipelines | BUILD_BUILDNUMBER |
| Bamboo | bamboo_buildNumber |
| Bitbucket | BITBUCKET_BUILD_NUMBER |
| Buildkite | BUILDKITE_BUILD_ID |
| Circle | CIRCLE_WORKFLOW_ID, CIRCLE_BUILD_NUM |
| Codeship | CI_BUILD_NUMBER |
| Codeship Basic | CI_BUILD_NUMBER |
| Codeship Pro | CI_BUILD_ID |
| Drone | DRONE_BUILD_NUMBER |
| GitLab | CI_PIPELINE_ID |
| Jenkins | BUILD_NUMBER |
| Semaphore | SEMAPHORE_EXECUTABLE_UUID |
| Travis | TRAVIS_BUILD_ID |
You can pass a different value to link agents to the same run. For example, if
you are using Jenkins and think the environment variable BUILD_TAG is more
unique than the environment variable BUILD_NUMBER, pass the BUILD_TAG value
via CLI
--ci-build-id flag.
cypress run --record --parallel --ci-build-id $BUILD_TAG
Run completion delay
During parallelization mode or when grouping runs, Cypress will wait for a specified amount of time before completing the test run in case any more relevant work remains. This is to compensate for various scenarios where CI machines could be backed-up in a queue.
This waiting period is called the run completion delay and it begins after the last known CI machine has completed as shown in the diagram below:
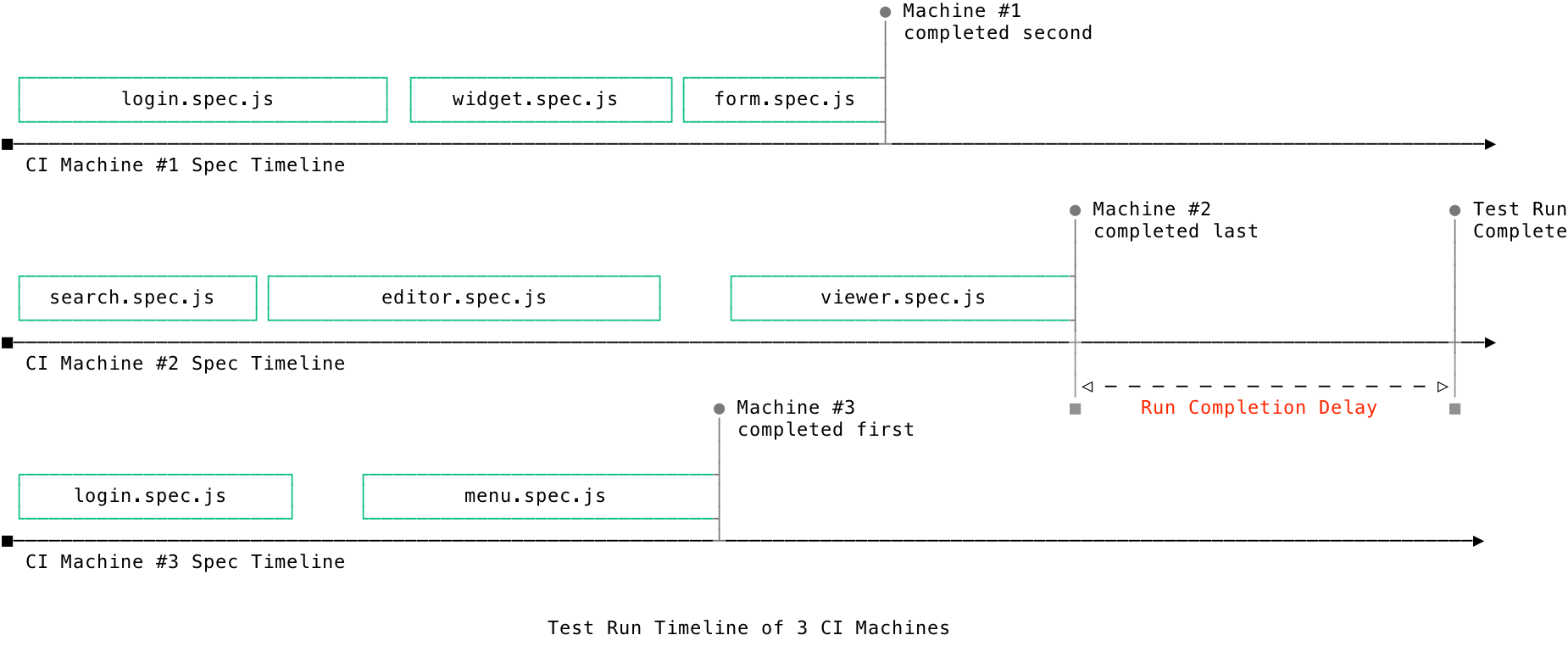
This delay is 60 seconds by default, but is configurable within Cypress Cloud project settings page.
Visualizing parallelization and groups in Cypress Cloud
You can see the result of each spec file that ran within Cypress Cloud in the run's Specs tab. Specs are visualized within a Timeline, Bar Chart, and Machines view.
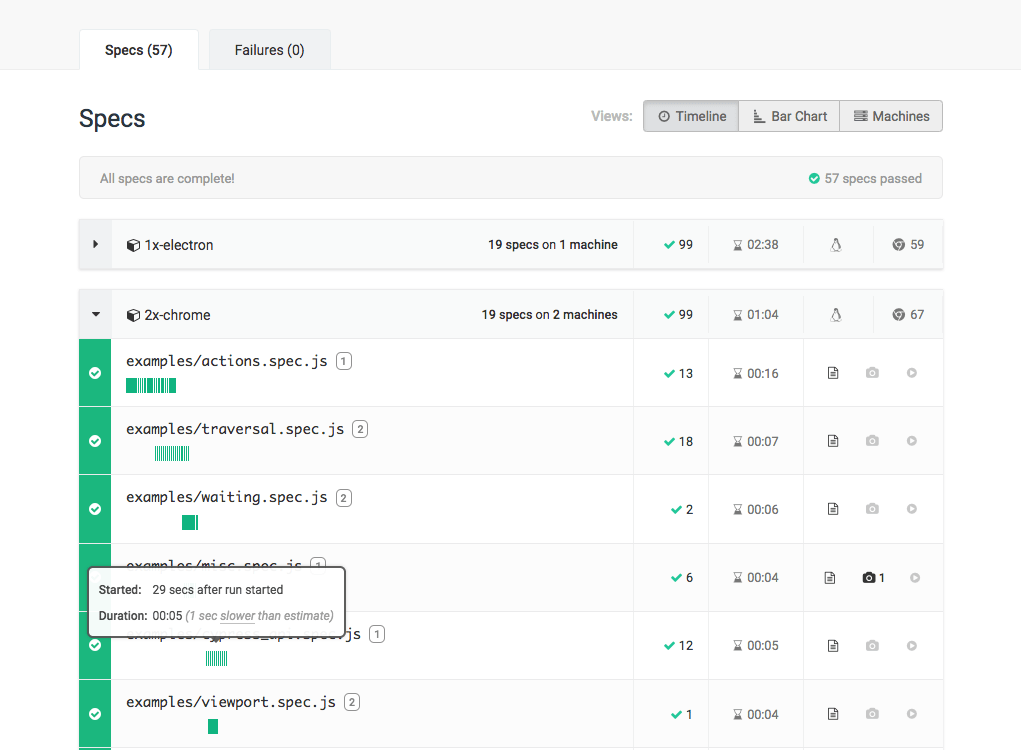
Timeline View
The Timeline View charts your spec files as they ran relative to each other. This is especially helpful when you want to visualize how your tests ran chronologically across all available machines.
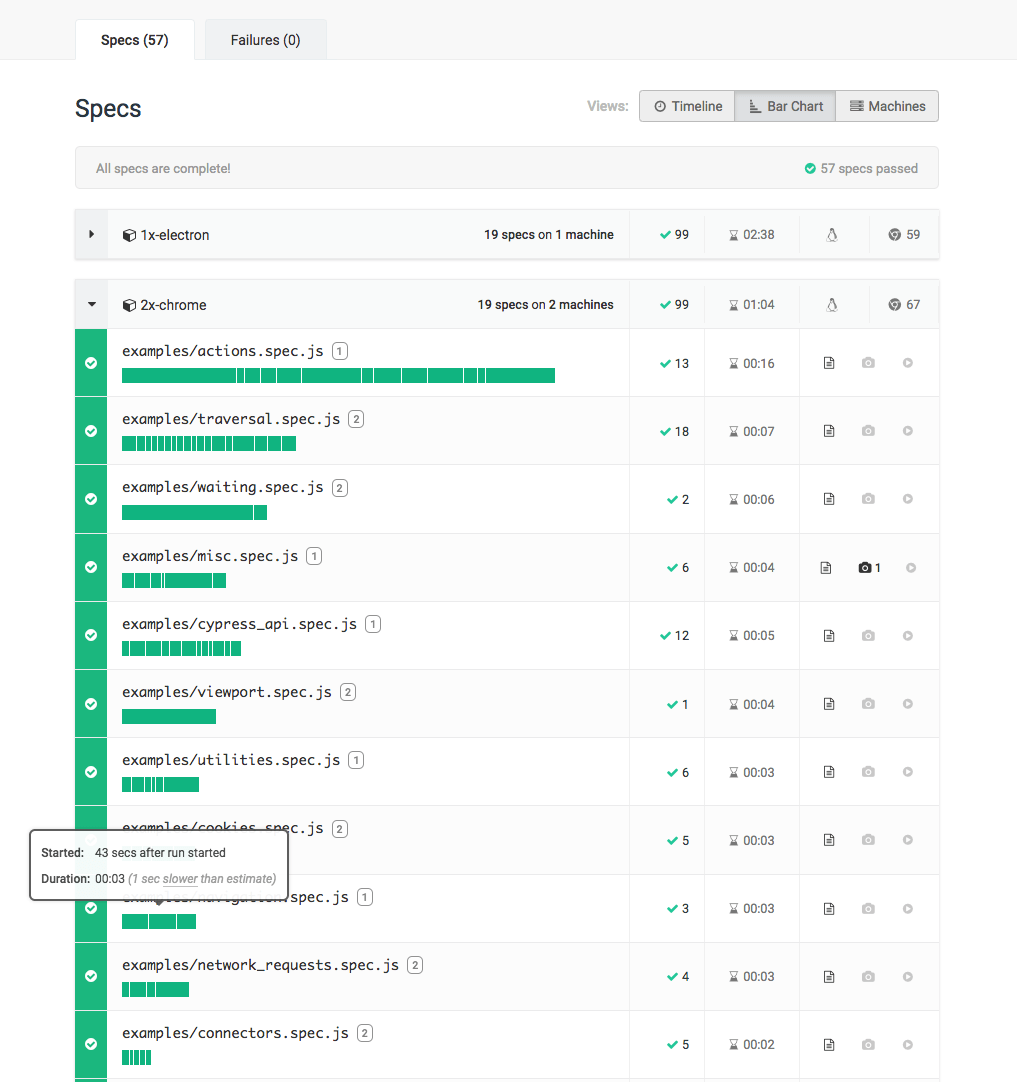
Bar Chart View
The Bar Chart View visualizes the duration of your spec files relative to each other.
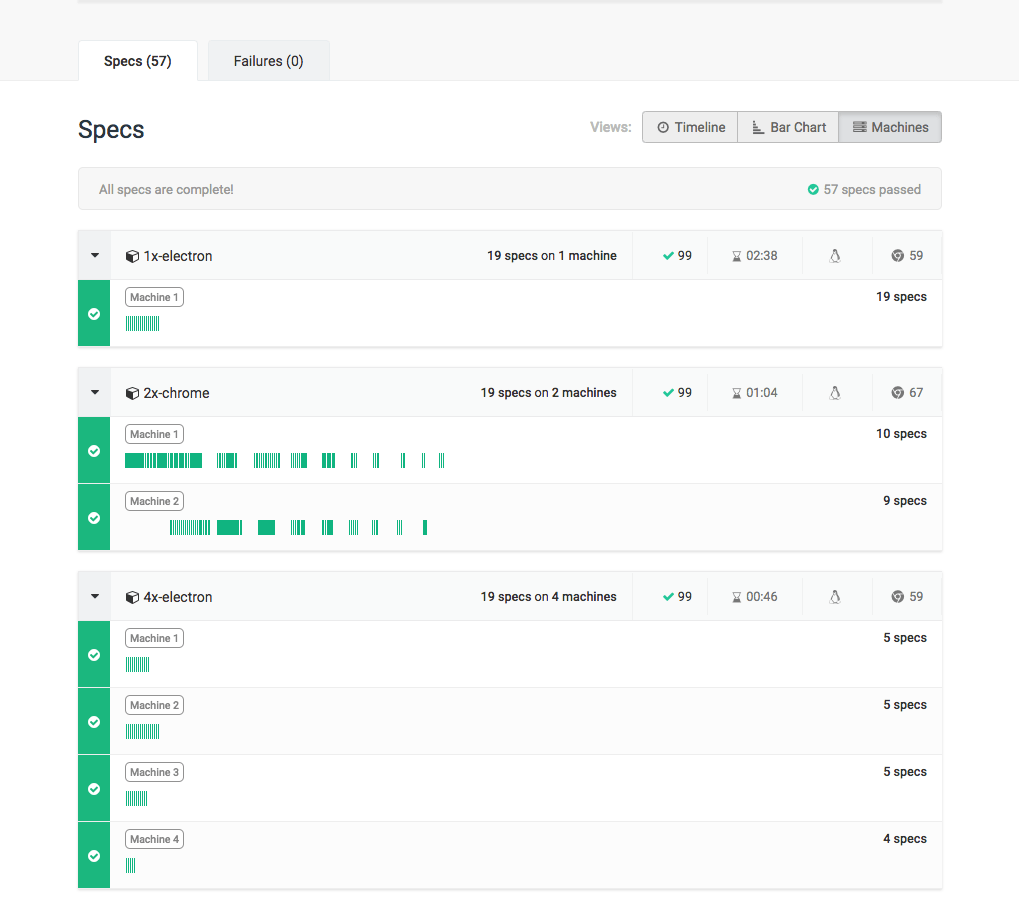
Machines View
The Machines View charts spec files by the machines that executed them. This view enables you to evaluate the contribution of each machine to the overall test run.
Next Steps
- Cypress Real World App runs parallelized CI jobs across multiple operating systems, browsers, and viewport sizes.
- Continuous Integration Guide
- Cross Browser Testing Guide
- Blog: Run Your End-to-end Tests 10 Times Faster with Automatic Test Parallelization
- CI Configurations in Kitchen Sink Example